Когда мы стали подозревать всюду нейросети
В 2024 году пользователи соцсетей обнаружили верный признак текста, сгенерированного с помощью ChatGPT, — длинное тире. Этого знака пунктуации нет на стандартной клавиатуре. Чтобы набрать его, пользователю нужно устанавливать специальную раскладку или использовать особые сочетания клавиш; кроме того, некоторые текстовые редакторы автоматически заменяют на тире дефис, отбитый пробелами. Но большинство людей этот знак не используют, зато они заметили, что его очень любит ChatGPT. Сопоставив эти два факта, многие сделали вывод: тире — верный маркер текста, сгенерированного большой языковой моделью.
Кажущаяся логика неверна. Из того, что большим языковым моделям свойственно употреблять правильные знаки препинания, не следует, что это их верный признак. Более того, компьютер использует тире ровно потому, что его очень любят использовать люди. Этот знак препинания стал особенно популярен в XIX веке: им часто пользовались Джейн Остин, Чарльз Диккенс, Герман Мелвилл и — особенно часто и экспрессивно — поэтесса Эмили Дикинсон. В России про тире тоже не забывают. В рассказе «Кавказский пленник» Лев Толстой использовал 332 тире — больше 16 на страницу. И это не совпадение: Шон Годеке, ведущий инженер GitHub, предполагает, что склонность часто использовать тире появилась в GPT, когда модель стали тренировать на большом количестве литературы столетней давности — как раз того периода, когда этот знак был особенно популярен.
Случай с тире довольно быстро превратился в мем, но вскоре были найдены новые «признаки нейроконтента», по которым люди стараются опознать сгенерированные тексты, — скажем, чрезмерное использование противопоставлений («это не просто.., а…») или парцелляции («…тут тоже пример…»). Стараются люди находить и новые способы отличать сгенерированные изображения, звуковые или видеофайлы. Если раньше «руку» компьютера почти всегда выдавали очевидные ошибки — лишние конечности, неконсистентность образа в серии изображений, — то с каждой новой итерацией порождение нейросетей все сложнее наверняка отличить от просто не слишком изобретательного человеческого творчества.
Базовая когнитивная эвристика изменяется. Традиционно люди оценивают надежность контента по поверхностным признакам: насколько профессионально он выглядит, насколько гладко написано. Многочисленные исследования годами показывали, что пользователи интернета обычно судят о достоверности контента по легкодоступным сигналам. Это была не целиком надежная, но работающая система. Теперь все чаще именно эти признаки автоматически считываются как маркеры машинного происхождения.
Британский философ Онора О’Нил еще в начале нулевых предупреждала: «Новые информационные технологии идеально подходят для распространения надежной информации, но они дислоцируют наши обычные способы оценивать чужие утверждения и решать, кому доверять». Растущая распространенность ИИ-контента довела этот процесс дислокации до предела.
«Проблема аутентичности возникает задолго до искусственного интеллекта, — говорит Полина Колозариди, исследовательница интернета и цифровой культуры. — Весь XX век мы тянулись к аутентичности, к подлинности, и каждое новое изобретение воспринимается как новый способ фальсифицировать реальность — от газет до искусственного интеллекта». В случае с ChatGPT произошло нечто новое: правила «удобного текста», которые раньше были имплицитными, вдруг стали видны — и потому кажутся теперь искусственными. «Это похоже на то, как приезжаешь в другой город и вдруг видишь, что там все правила стояния в очереди написаны явно, и понимаешь: а люди-то всегда так стояли, просто никто не формулировал», — объясняет Колозариди.
Нам кажется, что мы умеем отличать нейроконтент. Это не так
Люди уверены, что могут распознать ИИ-контент. Данные этого не подтверждают.
Одно из исследований 2025 года показало: точность различения сгенерированных и «человеческих» изображений колеблется между 61 и 63% — немногим лучше случайного угадывания. Специалист по кибербезопасности Перри Карпентер в книге «FAIK» (2024) приводит еще более пугающую статистику: даже когда людей предупреждали, что среди показанных им видео могут быть дипфейки, лишь 21,6% сумели верно их распознать.

При этом мы склонны переоценивать свою способность отличать сгенерированный контент. Как показывают создатели обзора «The Psychology of Fake News» (2021), самоуверенность напрямую связана с ошибками в оценке информации: «Исследования показывают, что чрезмерная уверенность может способствовать восприимчивости к ложной информации, возможно, потому, что она не позволяет людям замедлиться и включить рефлексивное мышление». Люди, убежденные в своей проницательности, чаще становятся жертвами обмана.
Именно в этом заключается опасность того, что люди при попытке распознать сгенерированный контент полагаются на поверхностные и неточные признаки вроде использования тех или иных знаков препинания. У них складывается ложное представление о своей способности отличать нейроконтент — и, как следствие, реальная способность снижается. А этот навык важен как никогда — и притом требует от нас больше сил, чем прежде. Индийский исследователь Мостафа Эйсса описывает растущее «бремя верификации» (verification burden) — когнитивную нагрузку от постоянной необходимости перепроверять то, что раньше принималось без колебаний.
Как недоверие играет на руку лжецам
В последнее десятилетие, говоря о фейк-ньюс, люди обычно имеют в виду то, что обманщики выдают ложную информацию за правду. Но с распространением доступных генерационных нейросетей и стремительным развитием качества их контента стала все виднее обратная проблема: теперь и правду можно объявить фейком. В твиттере шутят: «Мой адвокат добавляет водяной знак Sora на высококачественное видео преступления, которое я реально совершил». В этих мемах лишь доля шутки.
Правоведы Роберт Чесни и Даниэль Цитрон в 2019 году ввели понятие «дивиденд лжеца»: само существование реалистичных дипфейков дает виновным возможность отрицать подлинные свидетельства. Карпентер в книге «FAIK» объясняет: «Дивиденд лжеца позволяет виновным прятаться среди невиновных, используя неспособность публики отличить правду от вымысла как дымовую завесу».
Это больше не юридическая абстракция. Доклад ЮНЕСКО «Дипфейки и кризис знания» (2025) констатирует: «Дивиденд лжеца <…> создает двойной капкан, в котором не могут быть оправданы ни вера, ни неверие в свидетельства». Многие винят в стремительной актуализации этой проблемы столь же стремительное развитие генерационных нейросетей.
Исследовательница дезинформации Рене ДиРеста еще до появления общедоступных генерационных моделей отмечала: «Не нужно создавать фальшивое видео, чтобы эта технология оказала серьезное воздействие. Достаточно просто указать на то, что технология существует, — и можно поставить под сомнение достоверность всего настоящего».
ЮНЕСКО фиксирует формирование «порога синтетической реальности» — «точки, за которой люди уже не могут без технологической помощи отличить подлинное от сфабрикованного».
Полина Колозариди считает, что проблема не в самих нейросетях, а в том, что понимание реальности не успевает меняться с той же скоростью, что и реальность. Она ссылается на идею Кирилла Кобрина из книги «Шерлок Холмс и рождение современности» о том, что фигура детектива появляется в момент, когда перестают работать предшествующие системы ориентации. Город XIX века стал местом людей в одинаковых костюмах и котелках — и они чувствовали необходимость появления фигуры, способной по грязи на ботинках определить класс, вероисповедание и политические взгляды человека перед тобой. «Мне кажется, мы сейчас ожидаем такой же фигуры для цифровой эпохи, — говорит Колозариди, — такого детектива, который может распознавать людей и роботов, своих и чужих. До Шерлока Холмса не было такой фигуры для города. Вот и сейчас у нас нет такого типа познания: ни университет, ни что-то другое нас этому не учат».
Как недоверие разрушает социальные связи
Самое недооцениваемое последствие новой паранойи — не то, что мы можем поверить в фейки, и даже не то, что отвергаем подлинное. Чем чаще люди подозревают контент друг друга в искусственном происхождении (нередко безосновательно), тем сильнее это ударяет по социальным связям.
Мостафа Эйсса отмечает: «Если ИИ-контент становится широко распространенным или вызывает значительные споры вокруг аутентичности, это может разрушить социальную ткань сообщества. Доверие — ключевой элемент, скрепляющий сообщество; его эрозия может привести к снижению взаимодействия, уходу участников или даже фрагментации на более мелкие, изолированные группы, где воспринимаемую подлинность легче верифицировать».
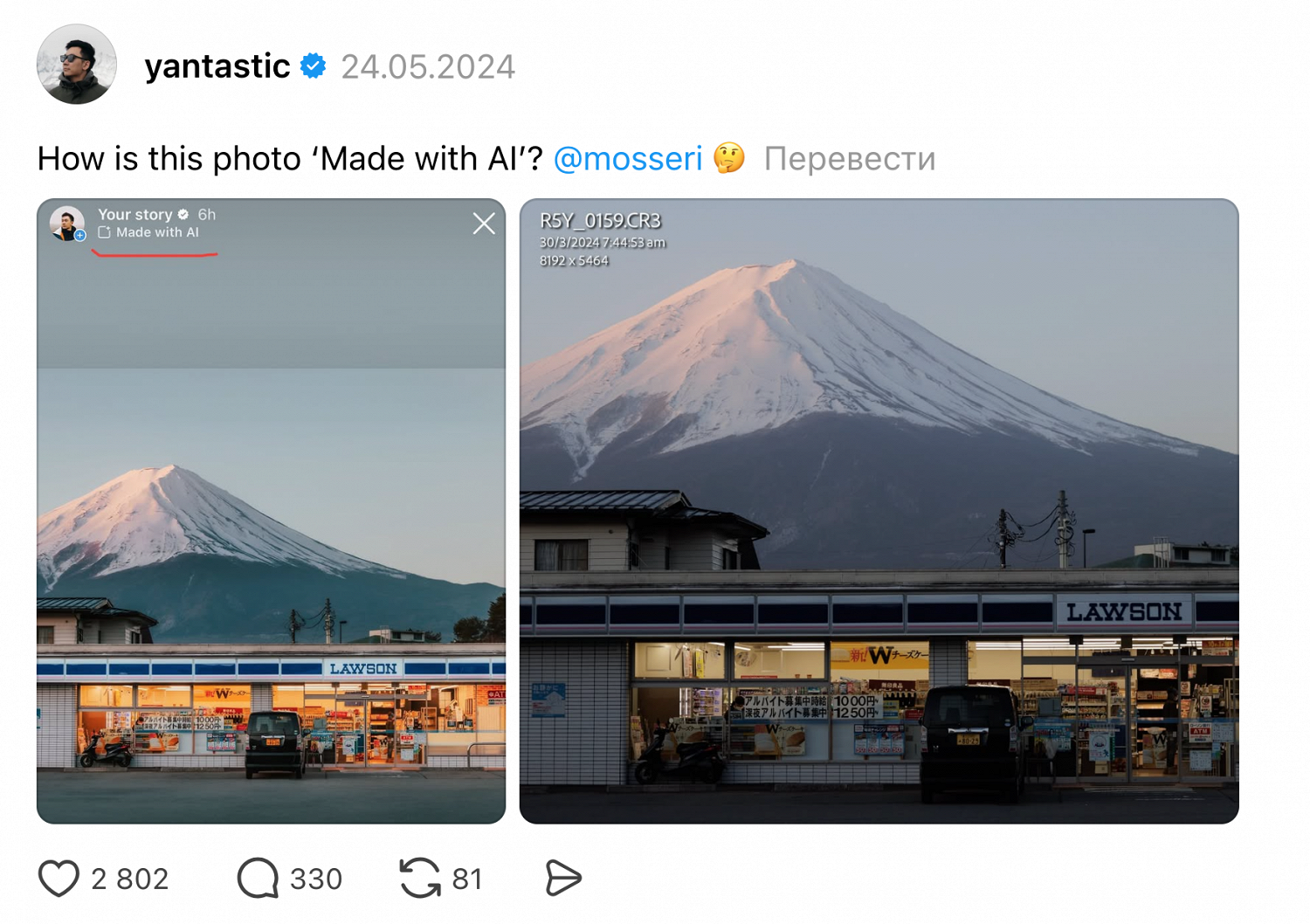
Для авторов, художников и просто людей, хорошо умеющих писать, это означает новую форму стигматизации. По иронии чем грамотнее написан текст, чем более профессиональной выглядит иллюстрация, тем больше подозрений. И эти подозрения напрямую влияют на отношение людей к контенту. Ирэн Рэй, исследовательница пользовательского опыта в Google, в своей работе показывает, что одна лишь информация об использовании ИИ снижает удовлетворенность аудитории контентом, даже если контент, который показывали разным группам, идентичен. «Мы обнаружили, что участники относились к создателю контента более негативно и были менее удовлетворены, когда считали, что использовался ИИ, — говорит она и приходит к выводу: — Информирование пользователей о применении ИИ может не оказывать ожидаемого эффекта в плане помощи потребителям при оценке контента, а вместо этого способно наносить ущерб отношениям между создателями и их аудиторией».
Капитуляция или адаптация?
Колозариди говорит, что ИИ-паранойя помогает людям уходить от необходимости понимания все более сложной реальности. «Когда мы пытаемся принять множественность и сложность мира, нам проще сказать: „Это сгенерировано, это придумал искусственный интеллект, это машины, это не мы, это не люди, это не мы так делаем, это не мы воюем“». Склонность всюду видеть генерацию обнуляет предмет дискуссии.
Есть ли выход? Авторы доклада ЮНЕСКО предлагают понятие «эпистемической агентности» (epistemic agency): если простыми словами, это способность человека выстраивать собственные рамки оценки знания, не опираясь на установленный конечный список признаков «человечности» или «искусственности». Они считают, что людям необходима глубокая когнитивная перестройка, выходящая за пределы простой медиаграмотности: «Эпистемическая агентность означает помощь учащимся в развитии персональных рамок оценки, а не принятие заранее установленных критериев верификации».
Адаптация будет неравномерной. Авторы статьи «Психология фейк-ньюс» утверждают, что лучше справятся те, кто привык замедляться и думать: «Более рефлексивные люди менее склонны верить ложному контенту и лучше различают правду и ложь, вне зависимости от того, совпадает ли новость с их политическими убеждениями».
Проблема в том, что этому замедлению прямо мешает распространение доступных нейросетей. Мы все чаще склонны делегировать им сложные, но необходимые мыслительные процессы. До абсурда эта практика была доведена с появлением встроенной нейросети в твиттере. Вместо того чтобы пытаться самостоятельно оценить правдоподобность утверждения, пользователи стали спрашивать: «@Grok, это правда?» — и принимать на веру любое утверждение, сгенерированное в ответ, особенно если оно соответствовало их предрассудкам. При этом точность Grok при фактчекинге не превышает 75%.
«Работа по тому, чтобы удерживать сложность мира в голове, — это непростое дело. Для нее нужно серьезное образование, понимание истории, социальных процессов, культуры, — отмечает Полина Колозариди. — Призывы использовать ИИ, прежде чем осмыслять, конечно, ей не способствуют». Парадоксальным образом способности выстраивать сложную аргументацию и анализировать информацию оказываются под угрозой именно тогда, когда эти качества особенно нужны.
Впрочем, исследователи не теряют осторожного оптимизма и верят, что человечество способно подстроиться под новую реальность, если будет прикладывать к этому усилия. «Наша высшая задача — не просто обнаруживать обман, но участвовать в коллективном проекте формирования того, как мы конструируем знание, и определения того, во что стоит верить», — пишут авторы доклада ЮНЕСКО.
«Я не верю в то, что это катастрофа, — говорит Колозариди. — Мне представляется, что мы увидим, как люди придумывают возможность прочертить границы там, где их раньше не было. Сам процесс этого перечерчивания чудовищный, но это не бессмысленное дело».